Loading
AI & Agents
Agentic AI, RAG, and ML in production
We design and ship agentic AI systems, retrieval-augmented knowledge platforms, and ML decisioning engines that go beyond a chat box - with evaluation harnesses, tracing, cost controls and human-in-the-loop oversight baked in.
10+
Agentic systems in production
15+
RAG pipelines deployed
Always
Eval-driven delivery
Built-in
Human-in-the-loop oversight

Reference build
Zero AI
The intelligence layer for the Zero ecosystem. A production-grade workspace unifying conversation, automation, blockchain actions and fintech workflows.
FastAPINext.jsPostgreSQLRedisOpenAIAnthropic
Built it ourselves
The blueprint we ship clients
Everything on this page is battle-tested in our own intelligence platform — the same architecture, evals and guardrails we deploy for you.
Agentic chat workspace
Streaming responses, tool calls, persistent memory and provider abstraction across OpenAI, Anthropic and self-hosted models.
Blockchain intelligence
Wallet balances, transaction queries and contract inspection through plain-English commands with full audit trail.
12 typed tools
Banking, knowledge search, ledger ops — every tool has a strict schema, RBAC gate and structured audit log.
Enterprise security
JWT auth, role-based permissions (free / premium / operator / admin), encrypted secrets and prompt guardrails.
Reference architecture
The agent stack, end to end
Seven layers, each independently auditable. We'll happily walk a CISO, regulator or board through every box — and the SLOs we hold each one to.
L7
Experience layer
Workspaces, chat surfaces, copilots and embedded agents. Streaming UX with cancelation, tool-call previews, citations on every answer.
Next.js 15Vercel AI SDKReact Server ComponentsOpenTelemetry-Web
L6
Orchestration
Planner-executor loops, deterministic graphs for regulated paths, agent-to-agent handoffs with typed contracts.
LangGraphCrewAIMicrosoft Agent FrameworkTemporal
L5
Tooling & function-calling
Strictly-typed tools backed by your existing APIs. Schema validation, RBAC gates, dry-run mode and structured audit logs on every invocation.
JSON SchemaZodMCPOpenAPITool whitelists
L4
Model routing
Cheap-first cascade: small models for triage, frontier models for hard reasoning. Multi-provider failover with per-tenant budget caps.
OpenRouterPortkeyFoundryBedrockVertex
L3
Reasoning models
Frontier (GPT-5, Claude 4.x, Gemini 2.x) and open-weights (Llama, Qwen, Mistral) — picked per task on quality × latency × cost.
OpenAIAnthropicGoogleMistralLlama-cppvLLM
L2
Retrieval & memory
Hybrid retrieval (BM25 + vectors + reranker), citation-enforced answers, episodic + semantic memory per tenant with TTL and right-to-erasure.
pgvectorPineconeKDB.AIQdrantCohere Rerank
L1
Observability & evals
Trace every prompt, tool call and token. Golden-set evals on every PR, drift dashboards in production, LLM-as-judge with human spot-checks.
OpenTelemetryLangfuseBraintrustHeliconeApp Insights
Eval harness
No vibes-based shipping
Every PR runs the golden dataset. Every release is gated on six axes. Every regression is a blocker — not a release-note footnote.
≥ 92%
Factuality
Answer claims grounded in retrieved sources. LLM-as-judge + human spot-checks.
100% on RAG
Citation present
Every claim has at least one verifiable citation, or refuses cleanly.
≥ 98%
Tool-call correctness
Schema-valid arguments, right tool chosen, idempotent on retries.
< 2.5s TTFT
Latency p95
Time-to-first-token and total resolution time per intent class.
0 critical
Refusal & safety
Jailbreak resistance, PII redaction, policy adherence per region.
Budget-gated
Cost per resolution
Tokens × model price per successful task, trended per feature.
Guardrails & governance
Safe to put in front of customers
Production AI is a regulatory surface, not a demo. Here's the controls plane we wrap around every model we ship.
Data residency
Your cloud, your tenancy, your KMS keys. Foundry, Bedrock, Vertex or air-gapped open-weights — never our servers.
Prompt firewall
Input/output classifiers for jailbreaks, PII, prompt injection and policy violations. Block, redact or log per route.
EU AI Act ready
Risk-tier classification, data lineage, decision logging, right-to-explanation and human-in-the-loop on irreversible actions.
Cost circuit breaker
Per-tenant budget caps, semantic dedupe, prompt caching and a hard daily ceiling that trips before finance does.
Drift monitoring
Production traffic sampled into eval queues; we ship a weekly drift report with regressions ranked by user impact.
Multi-provider failover
No single-vendor lock-in. Automatic spillover when a provider is down, rate-limited or violating your SLA.
Engagement
From kickoff to production in ~10 weeks
We start with evals, ship a vertical slice, then harden it for scale. No big-bang launches; no demoware that dies on contact with users.
Week 1-2
Discovery & evals
Map use-cases to risk tiers, build the golden dataset, agree the success metric. No code yet — just numbers.
Week 3-6
Vertical slice
One agent, one workflow, end-to-end through your stack with guardrails and observability wired from day one.
Week 7-10
Hardening & UAT
Red-team passes, load tests, SOC review, regulator walk-through. Ship the production runbook and on-call handbook.
Week 11+
Scale & iterate
New tools and intents added behind feature flags. Weekly drift report; monthly model bake-off; quarterly cost audit.
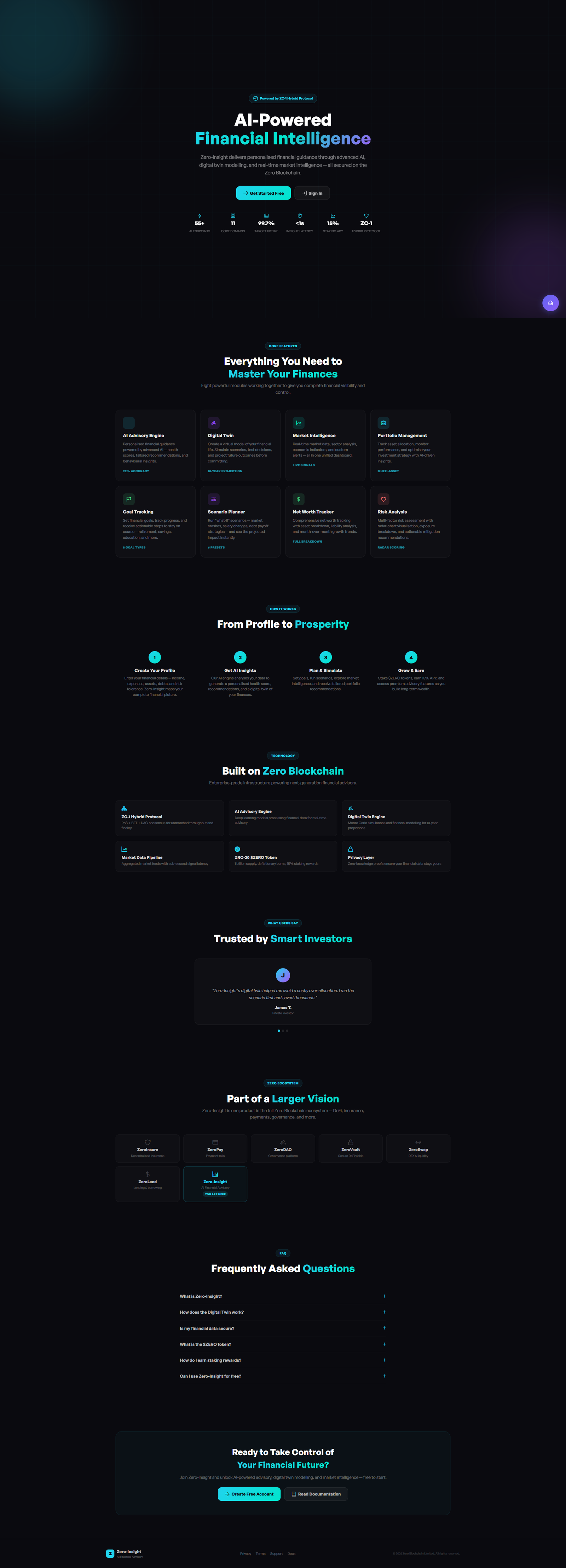
Agentic AI Systems
LLM agents with tools, memory & guardrails
We design and ship agentic systems that go beyond chat: tool-using agents, multi-agent workflows, retrieval pipelines, and human-in-the-loop oversight. Every system ships with an evaluation harness, prompt versioning, tracing, and cost controls.
Tool-using & multi-agent workflows
RAG pipelines with hybrid search
Eval harness + continuous monitoring
Tracing, cost & latency budgets
Human-in-the-loop oversight
AIAgentsLLM
RAG & Knowledge Systems
Search, ground, cite - at enterprise scale
Retrieval-augmented systems with hybrid search, reranking, citations, and tight evaluation - built on Azure AI Search, pgvector, or your stack of choice.
Hybrid (vector + BM25) retrieval
Reranking & citation grounding
Document ingestion pipelines
Evaluation harness for relevance
RAGSearchAI
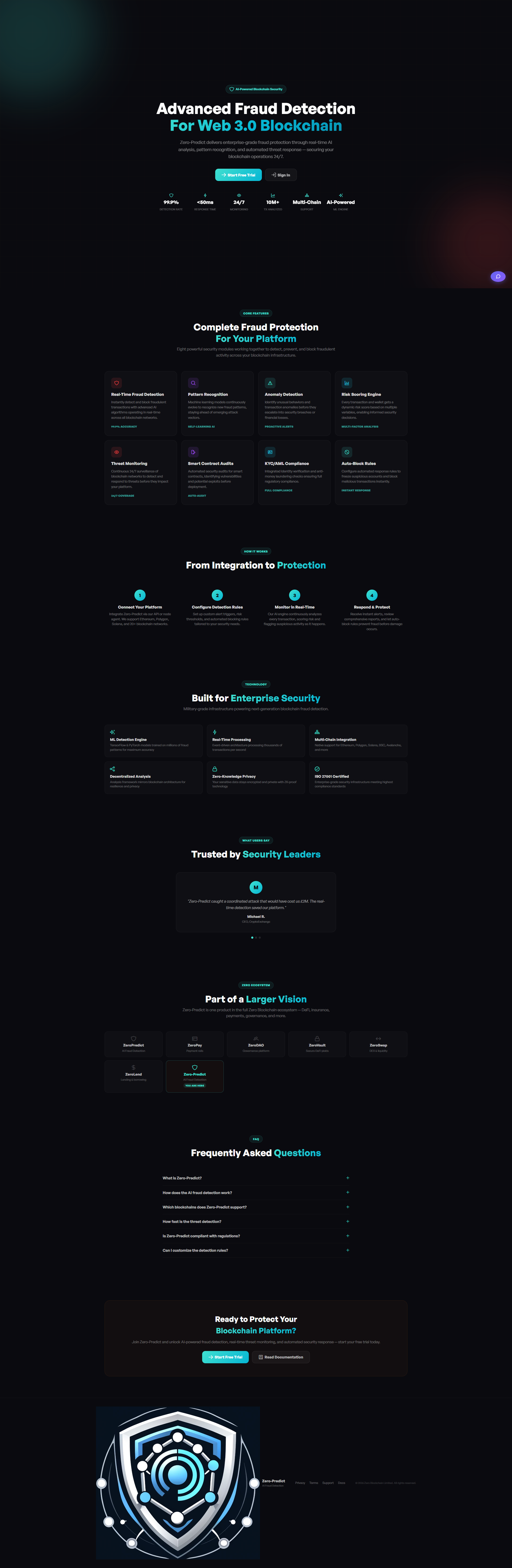
ML Decisioning Engines
Credit, risk & fraud models in production
Productionised ML for credit decisioning, risk scoring, and fraud - with explainability, fairness audits, and full MLOps lifecycle.
Credit scoring & affordability models
Real-time fraud detection
SHAP explainability
Fairness & drift monitoring
CI/CD for models (MLOps)
MLRiskDecisioning
Domain Copilots
In-product copilots for your users & staff
Embedded copilots that live inside your product or back-office: aware of your data, your permissions, and the action you actually want to take next.
Slash-commands & inline actions
Streaming UX with cancel & resume
Per-tenant memory & RBAC
Audit log on every tool call
Feature-flagged rollout
CopilotUXAI
Voice & Multimodal
Realtime voice agents, vision & document AI
Realtime voice agents, vision pipelines and document understanding for contact centres, field ops, and regulated workflows.
Realtime voice (sub-300ms turn-taking)
Vision: OCR, diagrams, ID & KYC
Document AI: contracts, forms, statements
Multilingual transcription & TTS
PII redaction at the edge
VoiceVisionMultimodal
Evaluation & Observability
Make AI quality measurable, every release
Golden datasets, LLM-as-judge harnesses, prompt versioning and production tracing - so you can ship AI changes with the same confidence as code changes.
Golden-set CI on every PR
LLM-as-judge with human spot-checks
Prompt versioning & A/B routing
Drift & regression dashboards
Cost-per-resolution analytics
EvalsObservabilityMLOps
AI Platform Engineering
The internal platform your AI teams need
Self-serve AI platforms: model gateway, prompt registry, eval CI, secrets & budgets - so every team in your org can ship safely without rebuilding the plumbing.
Multi-provider model gateway
Per-team budgets & rate limits
Prompt & tool registry
Shared eval & guardrail libraries
On-prem or air-gapped deployments
PlatformGatewayAI
Fine-tuning & Distillation
Smaller, cheaper, faster - your data, your model
When the frontier is too slow or too expensive: distil to a small open-weights model trained on your traffic, with eval gates and a safe fallback.
Supervised fine-tuning (SFT) & DPO
LoRA / QLoRA on open-weights
Synthetic data generation
Eval-gated promotion to production
Frontier-model fallback on uncertainty
Fine-tuningOpen-weightsAI
AI Safety & Governance
Audit-ready AI for regulated industries
EU AI Act readiness, prompt firewalls, red-teaming and decision logging for AI systems that have to stand up to a regulator, not just a demo.
EU AI Act risk-tier mapping
Prompt-injection & jailbreak red-team
PII redaction & data lineage
Decision logs & right-to-explanation
Model & vendor due-diligence packs
SafetyGovernanceCompliance
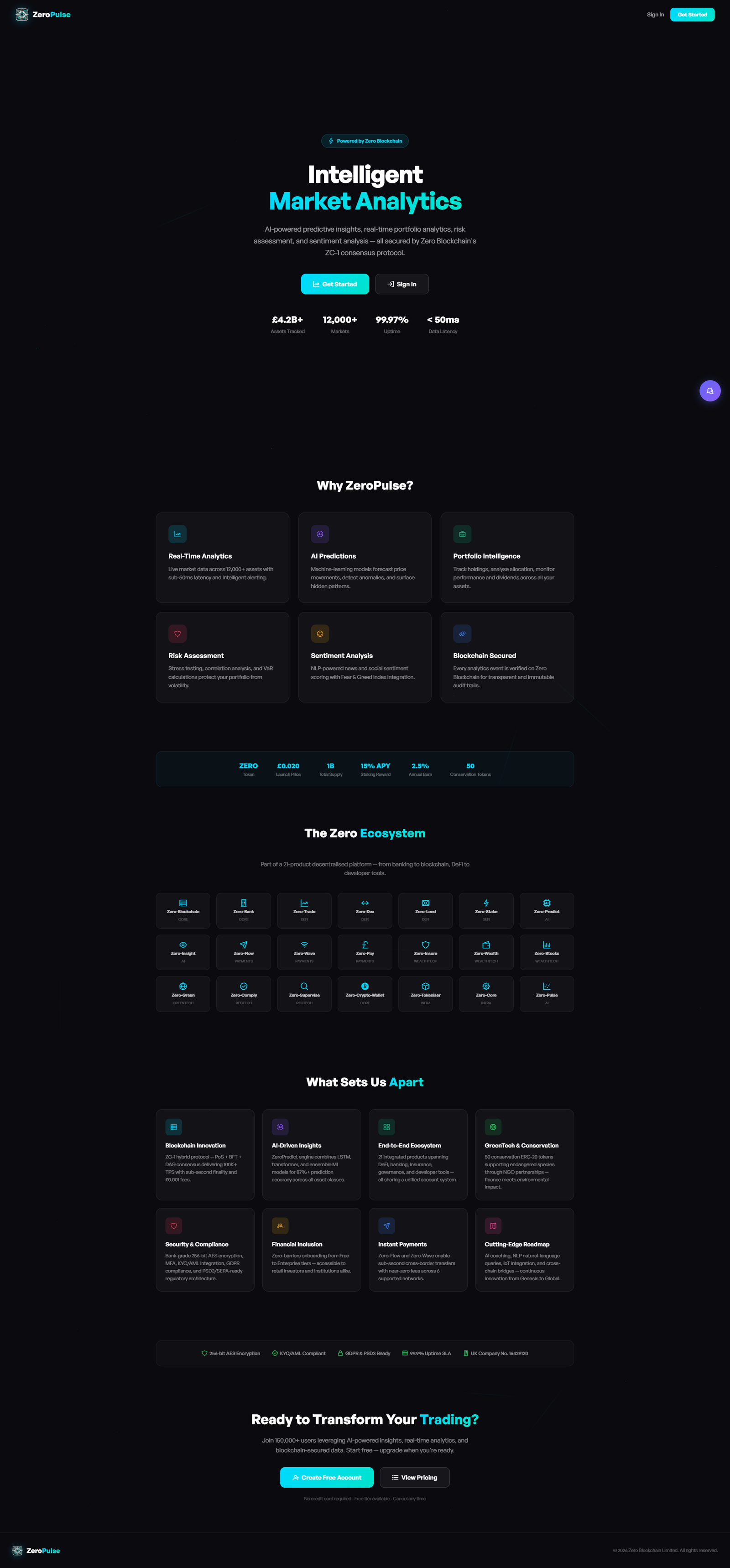
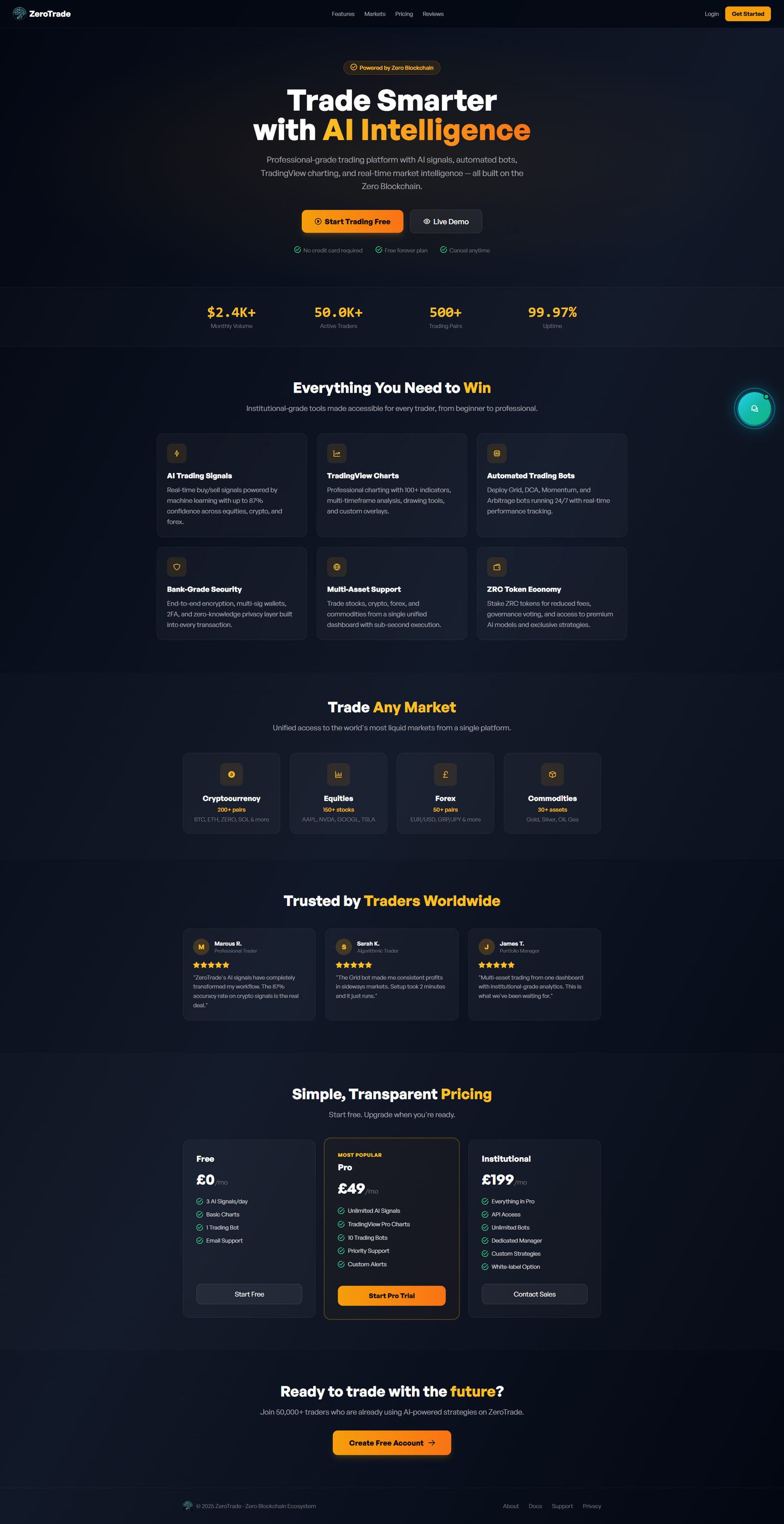
Flagship apps shipped in AI
Browse all apps4 production applications - each one fully built end-to-end. Click any to inspect every screen, flow and engineering decision.
How we work together
Three ways to engage
Pick the shape that fits your stage. We'll tell you honestly if a different one would serve you better.
Discovery sprint
1 - 2 weeksPin down the problem, the constraints and the smallest thing worth building.
- Stakeholder interviews & goal mapping
- Architecture spike + risk register
- Costed roadmap and clickable prototype
Fixed-scope build
4 - 16 weeksA defined deliverable, shipped to production with full handover.
- Milestone billing, weekly demos
- CI/CD, tests, docs, runbooks
- Two-week post-launch hyper-care
Embedded squad
Rolling, 3+ monthsSenior engineers integrate with your team and ship alongside you.
- Daily standups in your tooling
- Code reviews, mentoring, pairing
- Flexible scope, monthly retainer
Our process
From first call to second release
Five stops. No mystery. You always know what we're doing this week and what evidence we'll bring next week.
1
Discover
Goals, users, constraints, risks. We come back with a costed plan and a sharp scope.
2
Architect
Tech choices, data model, security & compliance. Decisions documented in ADRs.
3
Build
Iterative sprints, weekly demos, every change behind tests and code review.
4
Launch
Staged rollout, telemetry, runbooks, on-call cover. We babysit the first two weeks.
5
Iterate
Measure, learn, ship. Roadmap reviewed monthly against the metrics that matter.
Technology stack
The tools we ship with
Every chip below is in a production system somewhere. Size hints at how often it shows up across our ai work.
Python×3OpenAI×3Microsoft Agent Framework×2TypeScript×2OpenTelemetry×2Azure AI FoundryAzure AI Searchpgvectorscikit-learnXGBoostMLflowAzure MLVercel AI SDKNext.jsAnthropicOpenAI RealtimeAzure SpeechWhisperGeminiTesseractLangfuseBraintrustHeliconeApp InsightsPortkeyOpenRouterLiteLLMFoundryBedrockVertexLlamaQwenMistralUnslothAxolotlvLLMLakeraProtect AIAzure Content SafetyCustom classifiers
“Their eval harness caught three regressions before launch that our old vendor would have shipped to production. The agent now resolves 62% of tier‑1 tickets autonomously, with a clean audit trail for every decision.”
VP of Customer Operations
European insurance group
Common questions
Things people ask
Can't see yours? Drop us a line - we'll usually reply within the working day.
Ask a different questionThree layers. Retrieval grounded in your authoritative sources with citation enforcement; an eval harness that runs on every PR (factuality, refusal, citation‑present, latency); and structured tool‑calling so the model can’t answer outside the rails. We publish a confidence score and a “I don’t know” path — silence is better than fiction.